Program
The following example is an adverse events program. The program
demonstrates how multiple frequency tables can be combined into a single
report. This example also shows how a wide report can be wrapped
horizontally using the page_wrap feature of the
reporter package.
library(sassy)
library(procs)
options("logr.autolog" = TRUE,
"logr.notes" = FALSE,
"logr.on" = TRUE,
"procs.print" = FALSE)
# Get temp directory
tmp <- tempdir()
# Open log
lf <- log_open(file.path(tmp, "example2.log"))
# Get data
dir <- system.file("extdata", package = "sassy")
# Get Data ----------------------------------------------------------------
sep("Prepare Data")
# Create libname for csv data
libname(sdtm, dir, "csv", quiet = TRUE)
# Load data into workspace
lib_load(sdtm)
put("Filter DM data")
datastep(sdtm.DM,
keep = v(USUBJID, ARM, ARMCD),
where = expression(ARM != "SCREEN FAILURE"), {}) -> dm
put("Get population counts")
proc_freq(dm, tables = ARM,
output = long,
options = v(nopercent, nonobs)) -> arm_pop
put ("Create lookup for AE severity")
sevn <- c(MILD = 1, MODERATE = 2, SEVERE = 3) |> put()
put("Prepare table data")
datastep(sdtm.AE, merge = dm,
merge_by = "USUBJID",
merge_in = v(inA, inB),
keep = v(USUBJID, ARM, AESEV, AESEVN, AESOC, AEDECOD),
where = expression(inB == 1 & inA != 0),
{
AESEVN <- fapply(AESEV, sevn)
}) -> ae_sub
# Prepare Formats ---------------------------------------------------------
sep("Prepare Formats")
fc <- fcat(CNT = "%3d",
PCT = "(%5.1f)",
CAT2 = c(MILD = "Mild",
MODERATE = "Moderate",
SEVERE = "Severe"))
# Perform Calculations ----------------------------------------------------
sep("Perform Calculations")
put("Get SOC Frequencies")
proc_freq(ae_sub,
tables = v(AESOC * AESEV),
by = "ARM") -> ae_soc
put("Combine columns for SOC")
datastep(ae_soc,
format = fc,
rename = list(VAR1 = "VAR", CAT1 = "CAT"),
drop = v(VAR2, CNT, PCT),
{
VARORD <- 1
CNTPCT <- fapply2(CNT, PCT)
CAT2 <- fapply(CAT2)
}) -> ae_soc_c
put("Pivot SOC frequencies")
proc_transpose(ae_soc_c, id = v(BY, CAT2),
var = CNTPCT,
copy = v(VAR, VARORD),
by = CAT) -> ae_soc_t
put("Get PT Frequencies")
proc_freq(ae_sub,
tables = "AEDECOD * AESEV",
by = "ARM",
options = nonobs) -> ae_pt
put("Get unique SOC and PT combinations")
proc_sort(ae_sub, keep = v(AESOC, AEDECOD),
by = v(AESOC, AEDECOD), options = nodupkey) -> evnts
put("Combine columns for PT")
datastep(ae_pt,
format = fc,
rename = list(VAR1 = "VAR", CAT1 = "CAT"),
drop = v(VAR2, CNT, PCT),
{
VARORD <- 2
CNTPCT <- fapply2(CNT, PCT)
CAT2 <- fapply(CAT2)
}) -> ae_pt_c
put("Pivot PT frequencies")
proc_transpose(ae_pt_c, id = v(BY, CAT2),
var = CNTPCT,
copy = v(VAR, VARORD),
by = CAT) -> ae_pt_t
nms <- names(ae_soc_t)
put("Join in SOC")
datastep(ae_pt_t, merge = evnts, rename = c(CAT = "CAT2", AESOC = "CAT"),
merge_by = c(CAT = "AEDECOD"), {
CAT <- toTitleCase(tolower(CAT))
}) -> ae_pt_tj
put("Stack SOC and PT counts")
datastep(ae_soc_t, set = ae_pt_tj,
keep = c("VAR", "CAT", "CAT2", "VARORD",
find.names(ae_pt_tj, "ARM*")), {}) -> ae_soc_pt
aefinal <- proc_sort(ae_soc_pt, by = v( CAT, VARORD, CAT2))
# All Adverse Events ------------------------------------------------------
put("Get frequencies for all events")
proc_freq(ae_sub, tables = "AESEV", by = v(ARM)) -> allfreq
put("Combine all events.")
datastep(allfreq, format = fc,
drop = v(N, CNT, PCT),
{
CNTPCT <- fapply2(CNT, PCT)
CAT <- fapply(CAT, fc$CAT2)
}) -> allfreqm
put("Prepare data for reporting")
proc_transpose(allfreqm, id = v(BY, CAT),
var = CNTPCT, copy = VAR, name = CAT) -> allfreqt
# Final Data --------------------------------------------------------------
sep("Create final data frame")
datastep(allfreqt, set = aefinal,
keep = names(aefinal),
{
if (VAR == "AESEV")
CAT <- "All Adverse Events"
}) -> allfinal
# Print Report ----------------------------------------------------------
sep("Create and print report")
put("Create table object")
tbl <- create_table(allfinal, first_row_blank = TRUE, width = 9) |>
column_defaults(from = `ARM A.Mild`, to = `ARM D.Severe`, width = 1, align = "center") |>
spanning_header("ARM A.Mild", "ARM A.Severe", label = "ARM A", n = arm_pop["ARM A"]) |>
spanning_header("ARM B.Mild", "ARM B.Severe", label = "ARM B", n = arm_pop["ARM B"]) |>
spanning_header("ARM C.Mild", "ARM C.Severe", label = "ARM C", n = arm_pop["ARM C"]) |>
spanning_header("ARM D.Mild", "ARM D.Severe", label = "ARM D", n = arm_pop["ARM D"]) |>
stub(vars = c("CAT", "CAT2"), label = "System Organ Class\n Preferred Term", width = 5) |>
define(CAT, blank_after = TRUE) |>
define(CAT2, indent = .25) |>
define(`ARM A.Mild`, label = "Mild") |>
define(`ARM A.Moderate`, label = "Moderate") |>
define(`ARM A.Severe`, label = "Severe") |>
define(`ARM B.Mild`, label = "Mild", page_wrap = TRUE) |>
define(`ARM B.Moderate`, label = "Moderate") |>
define(`ARM B.Severe`, label = "Severe") |>
define(`ARM C.Mild`, label = "Mild", page_wrap = TRUE) |>
define(`ARM C.Moderate`, label = "Moderate") |>
define(`ARM C.Severe`, label = "Severe") |>
define(`ARM D.Mild`, label = "Mild", page_wrap = TRUE) |>
define(`ARM D.Moderate`,label = "Moderate") |>
define(`ARM D.Severe`, label = "Severe") |>
define(VAR, visible = FALSE) |>
define(VARORD, visible = FALSE)
put("Create report object")
rpt <- create_report(file.path(tmp, "example2.rtf"), output_type = "RTF", font = "Arial") |>
options_fixed(font_size = 10) |>
page_header("Sponsor: Company", "Study: ABC") |>
titles("Table 5.0", "Adverse Events by Maximum Severity", bold = TRUE) |>
add_content(tbl) |>
footnotes("Program: AE_Table.R",
"Note: Adverse events were coded using MedDRA Version 9.1") |>
page_footer(Sys.time(), "Confidential", "Page [pg] of [tpg]")
put("Print report")
res <- write_report(rpt)
# Clean Up ----------------------------------------------------------------
sep("Clean Up")
put("Remove library from workspace")
lib_unload(sdtm)
put("Close log")
log_close()
# Uncomment to view report
# file.show(res$modified_path)
# Uncomment to view log
# file.show(lf)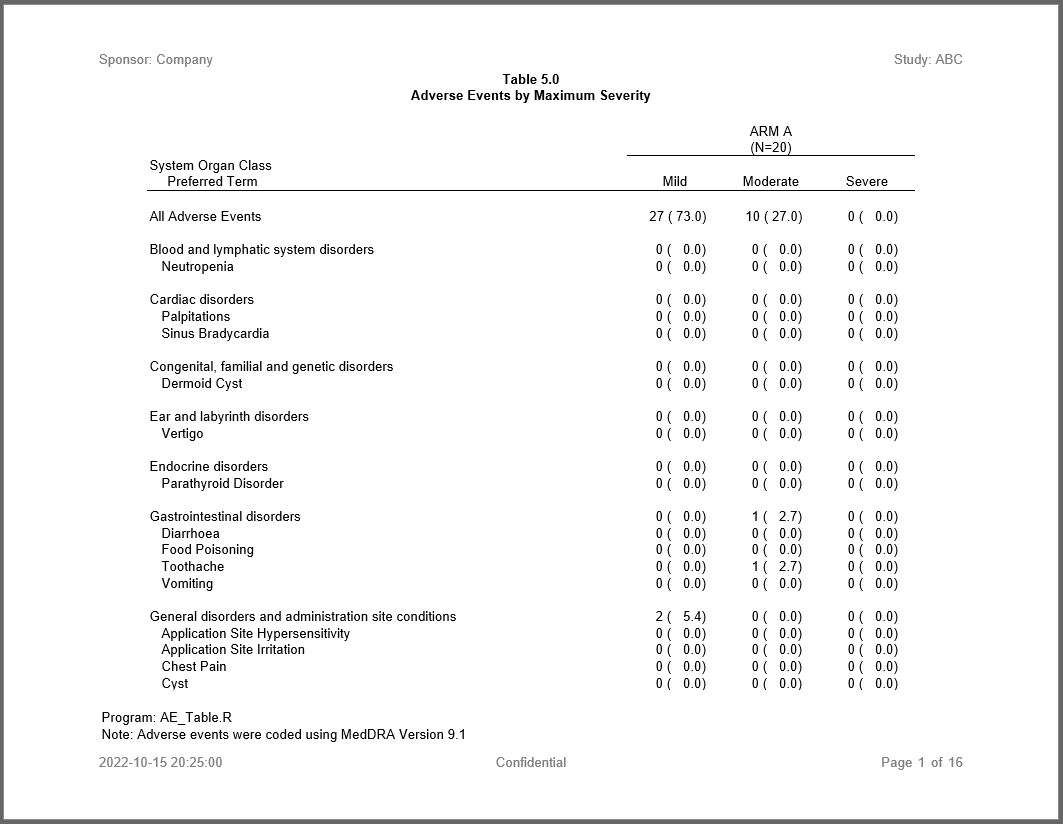
Log
And here is the log:
=========================================================================
Log Path: C:/Users/dbosa/AppData/Local/Temp/RtmpKQddL7/log/example2.log
Program Path: C:/Projects/Archytas/Demo/example2.R
Working Directory: C:/Projects/Archytas/Demo
User Name: dbosa
R Version: 4.2.1 (2022-06-23 ucrt)
Machine: SOCRATES x86-64
Operating System: Windows 10 x64 build 19044
Base Packages: stats graphics grDevices utils datasets methods base Other
Packages: tidylog_1.0.2 procs_0.0.9007 reporter_1.3.7 libr_1.2.6 fmtr_1.5.9
logr_1.3.3 common_1.0.5 sassy_1.0.8
Log Start Time: 2022-10-15 20:24:55
=========================================================================
=========================================================================
Prepare Data
=========================================================================
# library 'sdtm': 8 items
- attributes: csv not loaded
- path: ./data
- items:
Name Extension Rows Cols Size
1 AE csv 150 27 88.2 Kb
2 DA csv 3587 18 528 Kb
3 DM csv 87 24 45.3 Kb
4 DS csv 174 9 33.8 Kb
5 EX csv 84 11 26.1 Kb
6 IE csv 2 14 13.1 Kb
7 SV csv 685 10 70.1 Kb
8 VS csv 3358 17 467.2 Kb
LastModified
1 2020-09-18 14:30:23
2 2020-09-18 14:30:23
3 2020-09-18 14:30:23
4 2022-09-26 16:54:16
5 2020-09-18 14:30:23
6 2020-09-18 14:30:23
7 2020-09-18 14:30:24
8 2020-09-18 14:30:24
lib_load: library 'sdtm' loaded
Filter DM data
datastep: columns decreased from 24 to 3
# A tibble: 85 × 3
USUBJID ARM ARMCD
<chr> <chr> <chr>
1 ABC-01-049 ARM D 4
2 ABC-01-050 ARM B 2
3 ABC-01-051 ARM A 1
4 ABC-01-052 ARM C 3
5 ABC-01-053 ARM B 2
6 ABC-01-054 ARM D 4
7 ABC-01-055 ARM C 3
8 ABC-01-056 ARM A 1
9 ABC-01-113 ARM D 4
10 ABC-01-114 ARM B 2
# … with 75 more rows
# ℹ Use `print(n = ...)` to see more rows
Get population counts
proc_freq: input data set 85 rows and 3 columns
tables: ARM
view: TRUE
output: 1 datasets
# A tibble: 1 × 6
VAR STAT `ARM A` `ARM B` `ARM C`
<chr> <chr> <dbl> <dbl> <dbl>
1 ARM CNT 20 21 21
# … with 1 more variable: `ARM D` <dbl>
# ℹ Use `colnames()` to see all variable names
Create lookup for AE severity
MILD MODERATE SEVERE
1 2 3
Prepare table data
datastep: columns decreased from 27 to 6
# A tibble: 145 × 6
USUBJID ARM AESEV AESEVN AESOC AEDECOD
<chr> <chr> <chr> <dbl> <chr> <chr>
1 ABC-01… ARM D MODE… 2 Inve… BLOOD …
2 ABC-01… ARM D MODE… 2 Inve… BLOOD …
3 ABC-01… ARM D MILD 1 Musc… MUSCUL…
4 ABC-01… ARM D MILD 1 Nerv… HEADAC…
5 ABC-01… ARM D MODE… 2 Inve… LABORA…
6 ABC-01… ARM B MILD 1 Resp… UPPER …
7 ABC-01… ARM B MILD 1 Skin… RASH
8 ABC-01… ARM A MILD 1 Nerv… HEADAC…
9 ABC-01… ARM A MILD 1 Nerv… HEADAC…
10 ABC-01… ARM A MILD 1 Gene… INFLUE…
# … with 135 more rows
# ℹ Use `print(n = ...)` to see more rows
=========================================================================
Prepare Formats
=========================================================================
# A format catalog: 3 formats
- $CNT: type S, "%3d"
- $PCT: type S, "(%5.1f)"
- $CAT2: type V, 3 elements
=========================================================================
Perform Calculations
=========================================================================
Get SOC Frequencies
proc_freq: input data set 145 rows and 6 columns
tables: AESOC * AESEV
by: ARM
view: TRUE
output: 1 datasets
# A tibble: 240 × 8
BY VAR1 VAR2 CAT1 CAT2 N
<chr> <chr> <chr> <chr> <chr> <dbl>
1 ARM A AESOC AESEV Blood and… MILD 37
2 ARM A AESOC AESEV Blood and… MODE… 37
3 ARM A AESOC AESEV Blood and… SEVE… 37
4 ARM A AESOC AESEV Cardiac d… MILD 37
5 ARM A AESOC AESEV Cardiac d… MODE… 37
6 ARM A AESOC AESEV Cardiac d… SEVE… 37
7 ARM A AESOC AESEV Congenita… MILD 37
8 ARM A AESOC AESEV Congenita… MODE… 37
9 ARM A AESOC AESEV Congenita… SEVE… 37
10 ARM A AESOC AESEV Ear and l… MILD 37
# … with 230 more rows, and 2 more
# variables: CNT <dbl>, PCT <dbl>
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
Combine columns for SOC
datastep: columns decreased from 8 to 7
# A tibble: 240 × 7
BY VAR CAT CAT2 N VARORD
<chr> <chr> <chr> <chr> <dbl> <dbl>
1 ARM A AESOC Blood an… Mild 37 1
2 ARM A AESOC Blood an… Mode… 37 1
3 ARM A AESOC Blood an… Seve… 37 1
4 ARM A AESOC Cardiac … Mild 37 1
5 ARM A AESOC Cardiac … Mode… 37 1
6 ARM A AESOC Cardiac … Seve… 37 1
7 ARM A AESOC Congenit… Mild 37 1
8 ARM A AESOC Congenit… Mode… 37 1
9 ARM A AESOC Congenit… Seve… 37 1
10 ARM A AESOC Ear and … Mild 37 1
# … with 230 more rows, and 1 more
# variable: CNTPCT <chr>
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
Pivot SOC frequencies
proc_transpose: input data set 240 rows and 7 columns
by: CAT
var: CNTPCT
id: BY CAT2
copy: VAR VARORD
name: NAME
output dataset 20 rows and 16 columns
# A tibble: 20 × 16
VAR CAT VARORD NAME ARM A…¹ ARM A…²
<chr> <chr> <dbl> <chr> <chr> <chr>
1 AESOC Bloo… 1 CNTP… " 0 (… " 0 (…
2 AESOC Card… 1 CNTP… " 0 (… " 0 (…
3 AESOC Cong… 1 CNTP… " 0 (… " 0 (…
4 AESOC Ear … 1 CNTP… " 0 (… " 0 (…
5 AESOC Endo… 1 CNTP… " 0 (… " 0 (…
6 AESOC Gast… 1 CNTP… " 0 (… " 1 (…
7 AESOC Gene… 1 CNTP… " 2 (… " 0 (…
8 AESOC Infe… 1 CNTP… " 7 (… " 5 (…
9 AESOC Inju… 1 CNTP… " 0 (… " 0 (…
10 AESOC Inve… 1 CNTP… " 4 (… " 2 (…
11 AESOC Meta… 1 CNTP… " 0 (… " 0 (…
12 AESOC Musc… 1 CNTP… " 3 (… " 0 (…
13 AESOC Neop… 1 CNTP… " 0 (… " 0 (…
14 AESOC Nerv… 1 CNTP… " 7 (… " 0 (…
15 AESOC Psyc… 1 CNTP… " 0 (… " 1 (…
16 AESOC Rena… 1 CNTP… " 1 (… " 0 (…
17 AESOC Resp… 1 CNTP… " 2 (… " 1 (…
18 AESOC Skin… 1 CNTP… " 1 (… " 0 (…
19 AESOC Surg… 1 CNTP… " 0 (… " 0 (…
20 AESOC Vasc… 1 CNTP… " 0 (… " 0 (…
# … with 10 more variables:
# `ARM A.Severe` <chr>,
# `ARM B.Mild` <chr>,
# `ARM B.Moderate` <chr>,
# `ARM B.Severe` <chr>,
# `ARM C.Mild` <chr>,
# `ARM C.Moderate` <chr>, …
# ℹ Use `colnames()` to see all variable names
Get PT Frequencies
proc_freq: input data set 145 rows and 6 columns
tables: AEDECOD * AESEV
by: ARM
view: TRUE
output: 1 datasets
# A tibble: 876 × 7
BY VAR1 VAR2 CAT1 CAT2 CNT
<chr> <chr> <chr> <chr> <chr> <dbl>
1 ARM A AEDECOD AESEV ANXIETY MILD 0
2 ARM A AEDECOD AESEV ANXIETY MODE… 0
3 ARM A AEDECOD AESEV ANXIETY SEVE… 0
4 ARM A AEDECOD AESEV APPLICA… MILD 0
5 ARM A AEDECOD AESEV APPLICA… MODE… 0
6 ARM A AEDECOD AESEV APPLICA… SEVE… 0
7 ARM A AEDECOD AESEV APPLICA… MILD 0
8 ARM A AEDECOD AESEV APPLICA… MODE… 0
9 ARM A AEDECOD AESEV APPLICA… SEVE… 0
10 ARM A AEDECOD AESEV BACK PA… MILD 2
# … with 866 more rows, and 1 more
# variable: PCT <dbl>
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
Get unique SOC and PT combinations
proc_sort: input data set 73 rows and 6 columns
by: AESOC AEDECOD
keep: AESOC AEDECOD
order: a a
nodupkey: TRUE
output data set 73 rows and 2 columns
# A tibble: 73 × 2
AESOC AEDECOD
<chr> <chr>
1 Blood and lymphatic system diso… NEUTRO…
2 Cardiac disorders PALPIT…
3 Cardiac disorders SINUS …
4 Congenital, familial and geneti… DERMOI…
5 Ear and labyrinth disorders VERTIGO
6 Endocrine disorders PARATH…
7 Gastrointestinal disorders DIARRH…
8 Gastrointestinal disorders FOOD P…
9 Gastrointestinal disorders TOOTHA…
10 Gastrointestinal disorders VOMITI…
# … with 63 more rows
# ℹ Use `print(n = ...)` to see more rows
Combine columns for PT
datastep: columns decreased from 7 to 6
# A tibble: 876 × 6
BY VAR CAT CAT2 VARORD CNTPCT
<chr> <chr> <chr> <chr> <dbl> <chr>
1 ARM A AEDECOD ANXIE… Mild 2 " 0 …
2 ARM A AEDECOD ANXIE… Mode… 2 " 0 …
3 ARM A AEDECOD ANXIE… Seve… 2 " 0 …
4 ARM A AEDECOD APPLI… Mild 2 " 0 …
5 ARM A AEDECOD APPLI… Mode… 2 " 0 …
6 ARM A AEDECOD APPLI… Seve… 2 " 0 …
7 ARM A AEDECOD APPLI… Mild 2 " 0 …
8 ARM A AEDECOD APPLI… Mode… 2 " 0 …
9 ARM A AEDECOD APPLI… Seve… 2 " 0 …
10 ARM A AEDECOD BACK … Mild 2 " 2 …
# … with 866 more rows
# ℹ Use `print(n = ...)` to see more rows
Pivot PT frequencies
proc_transpose: input data set 876 rows and 6 columns
by: CAT
var: CNTPCT
id: BY CAT2
copy: VAR VARORD
name: NAME
output dataset 73 rows and 16 columns
# A tibble: 73 × 16
VAR CAT VARORD NAME ARM A…¹ ARM A…²
<chr> <chr> <dbl> <chr> <chr> <chr>
1 AEDE… ANXI… 2 CNTP… " 0 (… " 0 (…
2 AEDE… APPL… 2 CNTP… " 0 (… " 0 (…
3 AEDE… APPL… 2 CNTP… " 0 (… " 0 (…
4 AEDE… BACK… 2 CNTP… " 2 (… " 0 (…
5 AEDE… BASA… 2 CNTP… " 0 (… " 0 (…
6 AEDE… BLOO… 2 CNTP… " 0 (… " 0 (…
7 AEDE… BLOO… 2 CNTP… " 0 (… " 0 (…
8 AEDE… BLOO… 2 CNTP… " 0 (… " 1 (…
9 AEDE… BLOO… 2 CNTP… " 1 (… " 1 (…
10 AEDE… BLOO… 2 CNTP… " 0 (… " 0 (…
# … with 63 more rows, 10 more variables:
# `ARM A.Severe` <chr>,
# `ARM B.Mild` <chr>,
# `ARM B.Moderate` <chr>,
# `ARM B.Severe` <chr>,
# `ARM C.Mild` <chr>,
# `ARM C.Moderate` <chr>, …
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
Join in SOC
datastep: columns increased from 16 to 17
# A tibble: 73 × 17
VAR CAT2 VARORD NAME ARM A…¹ ARM A…²
<chr> <chr> <dbl> <chr> <chr> <chr>
1 AEDE… Anxi… 2 CNTP… " 0 (… " 0 (…
2 AEDE… Appl… 2 CNTP… " 0 (… " 0 (…
3 AEDE… Appl… 2 CNTP… " 0 (… " 0 (…
4 AEDE… Back… 2 CNTP… " 2 (… " 0 (…
5 AEDE… Basa… 2 CNTP… " 0 (… " 0 (…
6 AEDE… Bloo… 2 CNTP… " 0 (… " 0 (…
7 AEDE… Bloo… 2 CNTP… " 0 (… " 0 (…
8 AEDE… Bloo… 2 CNTP… " 0 (… " 1 (…
9 AEDE… Bloo… 2 CNTP… " 1 (… " 1 (…
10 AEDE… Bloo… 2 CNTP… " 0 (… " 0 (…
# … with 63 more rows, 11 more variables:
# `ARM A.Severe` <chr>,
# `ARM B.Mild` <chr>,
# `ARM B.Moderate` <chr>,
# `ARM B.Severe` <chr>,
# `ARM C.Mild` <chr>,
# `ARM C.Moderate` <chr>, …
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
Stack SOC and PT counts
datastep: columns started with 16 and ended with 16
# A tibble: 93 × 16
VAR CAT CAT2 VARORD ARM A…¹ ARM A…² ARM A…³ ARM B…⁴ ARM B…⁵ ARM B…⁶ ARM C…⁷ ARM C…⁸
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 AESOC Blood a… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (…
2 AESOC Cardiac… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
3 AESOC Congeni… <NA> 1 " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (… " 0 (…
4 AESOC Ear and… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (…
5 AESOC Endocri… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (…
6 AESOC Gastroi… <NA> 1 " 0 (… " 1 (… " 0 (… " 4 (… " 1 (… " 0 (… " 0 (… " 0 (…
7 AESOC General… <NA> 1 " 2 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 3 (… " 0 (…
8 AESOC Infecti… <NA> 1 " 7 (… " 5 (… " 0 (… " 7 (… " 1 (… " 0 (… " 6 (… " 3 (…
9 AESOC Injury,… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (…
10 AESOC Investi… <NA> 1 " 4 (… " 2 (… " 0 (… " 1 (… " 0 (… " 0 (… " 2 (… " 1 (…
# … with 83 more rows, 4 more variables: `ARM C.Severe` <chr>, `ARM D.Mild` <chr>,
# `ARM D.Moderate` <chr>, `ARM D.Severe` <chr>, and abbreviated variable names
# ¹`ARM A.Mild`, ²`ARM A.Moderate`, ³`ARM A.Severe`, ⁴`ARM B.Mild`, ⁵`ARM B.Moderate`,
# ⁶`ARM B.Severe`, ⁷`ARM C.Mild`, ⁸`ARM C.Moderate`
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
proc_sort: input data set 93 rows and 16 columns
by: CAT VARORD CAT2
keep: VAR CAT CAT2 VARORD ARM A.Mild ARM A.Moderate ARM A.Severe ARM B.Mild ARM B.Moderate ARM B.Severe ARM C.Mild ARM C.Moderate ARM C.Severe ARM D.Mild ARM D.Moderate ARM D.Severe
order: a a a
nodupkey: FALSE
output data set 93 rows and 16 columns
# A tibble: 93 × 16
VAR CAT CAT2 VARORD ARM A…¹ ARM A…² ARM A…³ ARM B…⁴ ARM B…⁵ ARM B…⁶ ARM C…⁷ ARM C…⁸
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 AESOC Blood… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (…
2 AEDECOD Blood… Neut… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (…
3 AESOC Cardi… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
4 AEDECOD Cardi… Palp… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
5 AEDECOD Cardi… Sinu… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
6 AESOC Conge… <NA> 1 " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (… " 0 (…
7 AEDECOD Conge… Derm… 2 " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (… " 0 (…
8 AESOC Ear a… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (…
9 AEDECOD Ear a… Vert… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (…
10 AESOC Endoc… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (…
# … with 83 more rows, 4 more variables: `ARM C.Severe` <chr>, `ARM D.Mild` <chr>,
# `ARM D.Moderate` <chr>, `ARM D.Severe` <chr>, and abbreviated variable names
# ¹`ARM A.Mild`, ²`ARM A.Moderate`, ³`ARM A.Severe`, ⁴`ARM B.Mild`, ⁵`ARM B.Moderate`,
# ⁶`ARM B.Severe`, ⁷`ARM C.Mild`, ⁸`ARM C.Moderate`
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
Get frequencies for all events
proc_freq: input data set 145 rows and 6 columns
tables: AESEV
by: ARM
view: TRUE
output: 1 datasets
# A tibble: 12 × 6
BY VAR CAT N CNT PCT
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 ARM A AESEV MILD 37 27 73.0
2 ARM A AESEV MODERATE 37 10 27.0
3 ARM A AESEV SEVERE 37 0 0
4 ARM B AESEV MILD 32 24 75
5 ARM B AESEV MODERATE 32 6 18.8
6 ARM B AESEV SEVERE 32 2 6.25
7 ARM C AESEV MILD 36 29 80.6
8 ARM C AESEV MODERATE 36 7 19.4
9 ARM C AESEV SEVERE 36 0 0
10 ARM D AESEV MILD 40 31 77.5
11 ARM D AESEV MODERATE 40 9 22.5
12 ARM D AESEV SEVERE 40 0 0
Combine all events.
datastep: columns decreased from 6 to 4
# A tibble: 12 × 4
BY VAR CAT CNTPCT
<chr> <chr> <chr> <chr>
1 ARM A AESEV Mild " 27 ( 73.0)"
2 ARM A AESEV Moderate " 10 ( 27.0)"
3 ARM A AESEV Severe " 0 ( 0.0)"
4 ARM B AESEV Mild " 24 ( 75.0)"
5 ARM B AESEV Moderate " 6 ( 18.8)"
6 ARM B AESEV Severe " 2 ( 6.2)"
7 ARM C AESEV Mild " 29 ( 80.6)"
8 ARM C AESEV Moderate " 7 ( 19.4)"
9 ARM C AESEV Severe " 0 ( 0.0)"
10 ARM D AESEV Mild " 31 ( 77.5)"
11 ARM D AESEV Moderate " 9 ( 22.5)"
12 ARM D AESEV Severe " 0 ( 0.0)"
Prepare data for reporting
proc_transpose: input data set 12 rows and 4 columns
var: CNTPCT
id: BY CAT
copy: VAR
name: CAT
output dataset 1 rows and 14 columns
# A tibble: 1 × 14
VAR CAT ARM A…¹ ARM A…² ARM A…³ ARM B…⁴ ARM B…⁵ ARM B…⁶ ARM C…⁷ ARM C…⁸ ARM C…⁹ ARM D…˟
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 AESEV CNTPCT " 27 (… " 10 (… " 0 (… " 24 (… " 6 (… " 2 (… " 29 (… " 7 (… " 0 (… " 31 (…
# … with 2 more variables: `ARM D.Moderate` <chr>, `ARM D.Severe` <chr>, and abbreviated
# variable names ¹`ARM A.Mild`, ²`ARM A.Moderate`, ³`ARM A.Severe`, ⁴`ARM B.Mild`,
# ⁵`ARM B.Moderate`, ⁶`ARM B.Severe`, ⁷`ARM C.Mild`, ⁸`ARM C.Moderate`, ⁹`ARM C.Severe`,
# ˟`ARM D.Mild`
# ℹ Use `colnames()` to see all variable names
=========================================================================
Create final data frame
=========================================================================
datastep: columns increased from 14 to 16
# A tibble: 94 × 16
VAR CAT CAT2 VARORD ARM A…¹ ARM A…² ARM A…³ ARM B…⁴ ARM B…⁵ ARM B…⁶ ARM C…⁷ ARM C…⁸
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 AESEV All A… <NA> NA " 27 (… " 10 (… " 0 (… " 24 (… " 6 (… " 2 (… " 29 (… " 7 (…
2 AESOC Blood… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (…
3 AEDECOD Blood… Neut… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 1 (…
4 AESOC Cardi… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
5 AEDECOD Cardi… Palp… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
6 AEDECOD Cardi… Sinu… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (… " 0 (…
7 AESOC Conge… <NA> 1 " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (… " 0 (…
8 AEDECOD Conge… Derm… 2 " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (… " 0 (…
9 AESOC Ear a… <NA> 1 " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (…
10 AEDECOD Ear a… Vert… 2 " 0 (… " 0 (… " 0 (… " 0 (… " 1 (… " 0 (… " 0 (… " 0 (…
# … with 84 more rows, 4 more variables: `ARM C.Severe` <chr>, `ARM D.Mild` <chr>,
# `ARM D.Moderate` <chr>, `ARM D.Severe` <chr>, and abbreviated variable names
# ¹`ARM A.Mild`, ²`ARM A.Moderate`, ³`ARM A.Severe`, ⁴`ARM B.Mild`, ⁵`ARM B.Moderate`,
# ⁶`ARM B.Severe`, ⁷`ARM C.Mild`, ⁸`ARM C.Moderate`
# ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
=========================================================================
Create and print report
=========================================================================
Create table object
Create report object
Print report
# A report specification: 16 pages
- file_path: 'C:\Users\dbosa\AppData\Local\Temp\RtmpKQddL7/example2.rtf'
- output_type: RTF
- units: inches
- orientation: landscape
- margins: top 0.5 bottom 0.5 left 1 right 1
- line size/count: 9/42
- page_header: left=Sponsor: Company right=Study: ABC
- title 1: 'Table 5.0'
- title 2: 'Adverse Events by Maximum Severity'
- footnote 1: 'Program: AE_Table.R'
- footnote 2: 'Note: Adverse events were coded using MedDRA Version 9.1'
- page_footer: left=2022-10-15 20:25:00 center=Confidential right=Page [pg] of [tpg]
- content:
# A table specification:
- data: tibble 'allfinal' 94 rows 16 cols
- show_cols: all
- use_attributes: all
- width: 9
- spanning_header: from='ARM A.Mild' to='ARM A.Severe' 'ARM A' level=1
- spanning_header: from='ARM B.Mild' to='ARM B.Severe' 'ARM B' level=1
- spanning_header: from='ARM C.Mild' to='ARM C.Severe' 'ARM C' level=1
- spanning_header: from='ARM D.Mild' to='ARM D.Severe' 'ARM D' level=1
- stub: CAT CAT2 'System Organ Class
Preferred Term' width=5 align='left'
- define: CAT
- define: CAT2
- define: ARM A.Mild 'Mild'
- define: ARM A.Moderate 'Moderate'
- define: ARM A.Severe 'Severe'
- define: ARM B.Mild 'Mild' page_wrap='TRUE'
- define: ARM B.Moderate 'Moderate'
- define: ARM B.Severe 'Severe'
- define: ARM C.Mild 'Mild' page_wrap='TRUE'
- define: ARM C.Moderate 'Moderate'
- define: ARM C.Severe 'Severe'
- define: ARM D.Mild 'Mild' page_wrap='TRUE'
- define: ARM D.Moderate 'Moderate'
- define: ARM D.Severe 'Severe'
- define: VAR visible='FALSE'
- define: VARORD visible='FALSE'
=========================================================================
Clean Up
=========================================================================
Remove library from workspace
lib_sync: synchronized data in library 'sdtm'
lib_unload: library 'sdtm' unloaded
Close log
=========================================================================
Log End Time: 2022-10-15 20:25:01
Log Elapsed Time: 0 00:00:06
=========================================================================